1. 人工智能与安全概述¶
1.1. 人工智能的定义¶
人工智能(Artificial intelligence,AI)这个词的出现最早可以追溯至1956年的达特茅斯会议。1956年8月,在美国汉诺斯小镇的达特茅斯学院,以约翰·麦卡锡(John McCarthy)、马文·明斯基(Marvin Minsky)、克劳德·香农(Claude Shannon)、艾伦·纽厄尔(Allen Newell)、赫伯特·西蒙(Herbert Simon)等为首的科学家们相聚在一起,讨论如何让机器模拟人类的学习能力,并在此次会议中正式提出了“人工智能”这个概念。 图1.1.1 为主要参会者会议合影图。此次达特茅斯会议在人工智能的发展史上称得上是开天辟地的大事件。此后不久,人工智能就作为独立的学科方向吸引了一大批研究学者。

图1.1.1 从左往右:奥利弗·赛尔弗里纪(Oliver Selfridge)、纳撒尼尔·罗切斯特(Nathaniel Rochester)、雷·索洛莫洛夫(Ray Solomonoff)、马文·明斯基、特伦查德·摩尔(Trenchard More)、约翰·麦卡锡、克劳德·香农在参加1956年达特茅斯会议期间的合影。(照片来源:玛格丽特·明斯基(Margaret Minsky))¶
事实上,直到现在人工智能都没有一个非常明确且统一的定义。维基百科中给出的定义是:“人工智能就是机器展现出现的智能”;人工智能之父图灵对其给出的定义为:“人工智能是制造智能机器,尤其是智能计算机程序的科学技术”; 我国《人工智能标准化白皮书(2018版)》中给也给出了相应的定义:“人工智能是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术和应用系统。”
尽管没有统一的定义,但我们仍然可以知道人工智能的本质是一项研究如何让机器能够拥有人类智能的科学技术。它致力于研究人类如何思考、学习、决策,并将研究结果用于构建具有能够模拟、延伸甚至扩展人类智慧的智能系统。
1.2. 人工智能的发展¶
伴随着新冠疫情的爆发,人类历史迈入了二十一世纪二十年代。在疫情防控的各方各面,人工智能技术都发挥着不可忽视的作用,包括计算机辅助诊疗、药物研发、物资调度、在线课程、远程辅导、全球疫情监控、舆情分析等等。如今人工智能像水电一样深入到我们每一个人的日常生活之中,聊天机器人、语音助手、自动驾驶、智慧医疗、智慧城市、金融科技、文化与艺术创作等各式各样的应用正在逐步实现。在今天,人工智能的宏伟蓝图令人振奋,也正是在这样的背景下,我们更要去回顾人工智能发展的历史,以史为镜,可以知兴替。
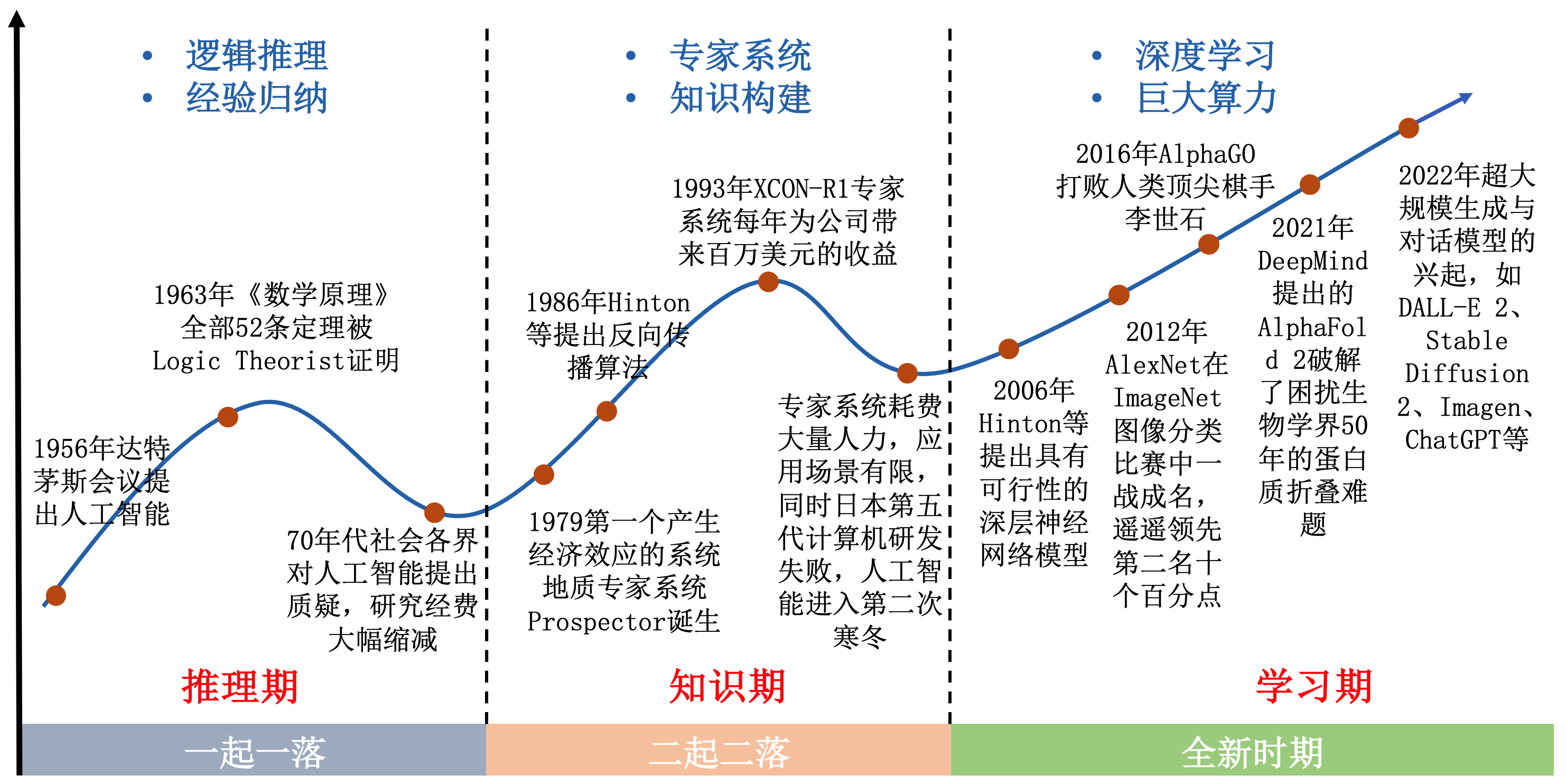
图1.2.1 人工智能简要发展历程¶
人工智能从诞生至今大约70年,期间经历了多次起起伏伏,很多资料将其称之为“三起三落”。 图1.2.1 简要展示了人工智能的发展历史,尽管不是一帆风顺,但总体仍然呈现出波浪式前进的趋势。本小节我们将按照一起一伏的发展周期对这段历史进行简要的回顾。
1.2.1. 三起三落¶
从热情高涨的开荒期到首次寒冬。 二十世纪五十年代,在图灵测试的提出和达特茅斯会议的举办之后,人工智能这一全新的研究方向开始受到全世界研究者的关注。在其后大约二十多年的时间里,人们见证了各式各样的人工智能系统从无到有的开荒过程。在这一时期中,大多数的研究工作是根据人类自身的经验和事实基础,进行一定的归纳总结,再基于一系列简单的规则和逻辑,设计出针对特定任务的计算机程序。因此在后来很多书籍和论文中,这一时期也被称为“推理期” (王珏 et al., 2006) 。1956年,艾伦·纽厄尔和赫伯特·西蒙编写了被称为“史上首个人工智能程序”的Logic Theorist (Newell and Simon, 1956) 。在当年,Logic Theorist证明了罗素的《数学原理》中的38条定理。1963年,全部52条定理得到证明,其中有一些定理的证明过程甚至比罗素和怀特黑德的原版证明更加优雅。1966年,世界上首款聊天机器人伊莉莎(Eliza)横空出世。她可以说是今天我们习以为常的语音助手诸如微软的小冰、苹果的Siri们的鼻祖。伊莉莎可以用英语和测试者进行交谈,甚至可以给人以夸赞和安慰。由于技术的局限性,她对人类对话的回应只不过是基于脚本库的关键词匹配,当人们与她进行长时间的对话后,很容易发现她回应的技巧。尽管在今天看来这些初步的智能系统不足为奇,但对于那个年代的人们来说,一个没有任何生命力的机器可以证明数学定理、翻译不同的语言、甚至用自然语言直接和人交流是难以置信的。 也正是这些惊人的工作让研究人员对人工智能的发展产生了过度乐观的预期,一些从业人员充满野心地预测20年内人类将实现完全的通用人工智能。但是随着研究的深入,越来越多的问题被暴露出来。一方面,基于简单规则的逻辑推理根本无法处理物理世界中纷繁复杂的现实情况;另一方面,尽管时下火热的人工神经网络的理论在当时就已被提出,但当时的计算机算力水平十分有限,远远无法支撑其庞大的训练开销。1973年,英国数学家詹姆士·莱特希尔(James Lighthill)向英国政府提交了一份关于人工智能发展近况的报告,指出当时的研究技术根本无法支撑起人工智能宏伟的目标,对该研究方向提出了严厉的批评。社会上开始有声音质疑人工智能的研究不过是一场骗局,随之而来的是各国政府经费的急剧缩减。因此在七十年代末期,人工智能的发展迎来了第一个寒冬。尽管如此,仍然有科学家在这一时期坚守在探索人工智能的道路上,在寒夜里举着火把前进。1979年,斯坦福大学发布了历史上第一款自动驾驶车Stanford Cart,它可以利用视觉传感器在杂乱的室内自主移动,尽管可能需要花费几个小时才能完成。
从重振旗鼓的发展期到二次寒冬。 在二十世纪七十年代末期,专家系统的出现打破了人工智能领域长达十年的寒冬。专家系统通过领域专家给计算机输入一系列的知识以及逻辑推理的规则,从而在特定领域能够模拟人类专家进行推理与判断。世界第一个专家系统DENDRAL由爱德华·费根鲍姆(Edward Feigenbaum)、布鲁斯·布坎南(Bruce G. Buchanan)、乔舒亚·莱德伯格(Joshua Lederberg)等人在1965年完成。研究人员将化学以及质谱仪相关的知识以及一系列的推理规则输入到DENDRAL中,使其能够根据有机化合物的分子式,推断出正确的分子结构,并且其准确度能够媲美人类化学家。由于专家系统在特定领域内的出色表现力,研究者开始将其应用在某些领域中代替人类专家,如医疗、金融领域等。1979年,成功开发的地质专家系统Prospector (Gaschnig, 1979) 是第一个产生经济效应的系统,并为公司节省了不菲的开销。1993年,美国DEC公司与卡耐基梅隆大学联合研发的XCON-R1专家系统更是每年为公司带来近百万美元的收益。这些专家系统的出现,使之前只在实验室“烧钱”的人工智能具有了产生部分实际经济效应的能力。
随着专家系统所展示的经济效应能力,资本重新流向人工智能领域,为人工智能研究带来了新鲜的活力,令其再次蓬勃发展了起来。在此时期,大量研究者专注于探索知识对于人工智能的影响,取得了许多重要成就,例如马文·明斯基提出的框架知识表示理论 (Minsky, 1974) ,以及兰德尔·戴维斯(Randall Davis)提出的大规模知识库构建与维护理论 (Davis, 1976) 。这些成就为现代知识图谱理论与推荐搜索技术打下了坚实的基础。此外,其他人工智能领分支域也同样硕果颇丰,如1976年提出的启发式搜索算法与计算机视觉理论体系以及1986年提出的反向传播算法 (Rumelhart et al., 1986) 、分布式并行处理等。这些研究都对后续人工智能领域的发展产生了深远的影响。 遗憾的是此次的繁荣也并不持久,大量资本的涌入在为人工智能领域提供燃料的同时也产生了大量的泡沫,使得专家系统的缺点更快地被展现出来。这些专家系统的研发需要投入大量的人力,他们难以升级且只能在特定的场景使用。这些缺点使得专家系统的研发产生了瓶颈,也导致了人们对专家系统乃至人工智能的通用性产生了质疑。到了八十年代末期,人工智能领域在美国战略计算促进大会的预算被大幅消减。无独有偶,日本耗资4亿多美元的第五代计算机研发计划也因达不到预期效果而宣告失败,该计划的目标是造出能够像人一样处理各种外界信息的通用人工智能机器。 至此,人工智能再次进入寒冬,这场由专家系统带来的人工智能短暂春天落下帷幕,由于在该时期研究者们普遍崇尚知识在人工智能系统中的作用,所以后续研究者们常称该时期为“知识期”。
集腋成裘进入百花齐放的新时代。 在人工智能第二次的没落之后,由于缺乏科研经费的支持,只有少数研究者还坚守在人工智能研究领域的前线。他们的努力最终为人工智能领域带来了第三次的飞跃。人工智能的第三次繁荣期被称为“学习期”。通过人工智能前两次发展的尝试,研究者发现人类完成通用图像、文本任务,如图像识别、情感分析等,难以找到固定的模式,此时简单的知识与规则已无法满足需求,而是需要让机器从数据中自主学习。2006年,杰弗里·辛顿(Geoffrey E. Hinton)在《科学》杂志上发表论文 (Hinton and Salakhutdinov, 2006) ,提出了具有可行性的深层神经网络模型,该论文被认为是第三次人工智能领域崛起的信号。随着互联网产业的崛起,大规模网络数据(如图像、文本、视频等)的获取成为了可能,而计算机硬件的发展也为深度学习的繁荣打下了基石。 2012年,由亚历克斯·克里泽夫斯基(Alex Krizhevsky)和杰弗里·辛顿等人提出的深度神经网络AlexNet (Krizhevsky et al., 2017) 在斯坦福大学举办的百万级别ImageNet图像分类挑战赛中一战成名,该网络利用图形处理器(graphics processing unit,GPU)进行快速学习,达到惊人的Top-5准确率84.6%,大幅领先第二名十个百分点。2015年,何凯明(Kaiming He)等人提出残差神经网络(residual neural network,ResNet) (He et al., 2015) ,首次在ImageNet图像分类任务上达到了超过人类的表现(Top-5识别错误率低于5.1%)。人工智能尤其是深度学习再次吸引了全世界的目光,各大公司、高校和科研院所纷纷成立人工智能实验室,投入大量经费支持相关研究。这其中包括由丹米斯·哈撒比斯(Demis Hassabis)、谢恩·莱格(Shane Legg)等人成立的人工智能公司DeepMind,以及由萨姆·阿尔特曼(Sam Altman)、伊隆·马斯克(Elon Musk)等人成立的OpenAI。我国华为、腾讯、阿里等头部企业也相继成立了人工智能实验室,力争在人工智能前沿抢占一定的领先优势。深度神经网络出色的(表征)学习能力并不局限于图像识别任务,而是在各行各业多点开花。2016年,由DeepMind公司打造的人工智能系统AlphaGO (Silver et al., 2016) 在曾被断言“人工智能不可能战胜人类”的围棋比赛中以4:1的成绩打败了顶尖人类棋手李世石。同年,机器人设计师大卫·汉森(David Hanson)成功研制了类人机器人Sophia,其拥有硅胶制成的皮肤,能够在智能算法的控制与电机的牵引下做出丰富且自然的面部表情,与人进行正常的语言对答和眼神交流。
自2012年以来的十年时间里,研究者提出了大量新型的深度神经网络模型,这些模型在诸多极具挑战性的学习任务上都取得了巨大的成功。这包括具有强大数据生成能力的生成对抗网络(generative adversarial network, GAN) (Goodfellow et al., 2014) 、具有强大序列表征与关系学习能力的Transformer模型 (Vaswani et al., 2017) 、具有序列-结构解析能力的AlphaFold 2 (Jumper et al., 2021) 、具有文本到图像生成能力的多模态模型DALL-E 2和Stable Diffusion 2、以及具有类人对话能力的ChatGPT模型等等。这些模型,如AlphaFold 2,甚至在一些长期困扰人类科学家的基础科学研究领域都取得了令人重大突破,正在催生大量新型交叉学科研究范式。 如今,我们正处在人工智能的第三次浪潮之中,在我们的日常生活中,处处都能发现人工智能的影子,例如大数据音乐、视频推荐、飞机场/火车站安检口的人脸识别系统等。未来,人工智能技术更新会越来越快,应用也会更加广泛,有望成为推动各领域产业变革和技术创新的主要源动力。
1.2.2. 重大突破¶
深蓝击败国际象棋冠军。 1997年注定是一个将被记录在人工智能史册的年份,因为在这一年,由IBM制造的超级计算机“深蓝”在标准的国际象棋比赛中击败了当时的国际象棋世界冠军卡斯帕罗夫。 “深蓝”最初起源于一个叫许峰雄(Feng-Hsiung Hsu)的中国台湾人在美国卡内基梅隆大学攻读博士学位的研究,许峰雄在美国卡内基·梅隆大学求学期间疯狂的迷恋上了计算机博弈这个领域,并在此之后几乎把所有的精力都投入到了这个领域的研究。1985年,许峰雄研制出第一个计算出棋路数的“ChipTest”,这个成果让他们在1987年的计算机博弈锦标赛中拔得头筹,也为他们积累了宝贵的经验以及日后持续投入研发的资金。皇天不负有心人,1988年许峰雄和他的合作者成功的研制出了“深思”(Deep Thought),这是一个配置有2个处理器、200块芯片,每秒钟能够执行70万个棋位分析的计算机,在当时战斗力大抵相当于一个级别段位教低的国际象棋大师。也就是在同一年,美国IBM公司发现了许峰雄以及他研制的深思,1989年,许雄峰携着他的深思加入IBM研究部门,继续着超级电脑的研究工作。 在1992年,IBM委任谭崇仁为超级电脑研究计划主管,领导研究小组开发专门用以分析国际象棋的“深蓝”(Deep Blue)超级电脑,名字深蓝取自“深思”和IBM“蓝色巨人”的结合。 4年后的1996年2月,深蓝第一次挑战俄罗斯国际象棋大师加里·卡斯帕罗夫(Garry Kasparov),这场比赛在费城举行并最终以2:4落败,尽管卡斯帕罗夫在这场比赛中取得了胜利,但是赢得并不轻松,其中一些神来之笔的棋路更是令卡斯帕罗夫头疼。虽然战败,但是对战国际顶尖棋手的战绩仍然使IBM的研究人员兴奋不已,在接下来的一年时间里,研究人员对深蓝进行了升级改造,甚至邀请了四位国际象棋大师作为深蓝的陪练。经过长达一年的准备,1997年5月11日,经过改良的深蓝再度挑战卡斯帕罗夫,并以3.5:2.5战胜卡斯帕罗夫,成为第一个在标准比赛时间内击败国际象棋世界冠军的计算机系统。国际象棋曾经一度被认为是人工智能永远无法攻克的智力游戏,而如今人工智能已可以战胜世界冠军,这给人们带来对人工智能技术的无限期待,以及从事人工智能研究的兴趣与信心。
深度学习模型在图像识别任务上超越人类。 2012年,为了证明深度学习的潜力,杰弗里·辛顿带领研究团队参加了ImageNet大规模(百万级)图像识别挑战赛,并提出了对深度学习影响深远的AlexNet网络 (Krizhevsky et al., 2017) 。AlexNet网络以超过第二名10%以上的Top-5准确率夺得了比赛的冠军,自此深度学习重新进入人们的视野并一发不可收拾,进入深度学习快速发展的黄金十年。如前面所述,这十年来,涌现了许许多多的神经网络结构并不断的刷新着各类记录。在计算机视觉领域,以2014年的VGGNet (Simonyan and Zisserman, 2015) 、Inception-Net (Szegedy et al., 2016) 以及2015年的ResNet网络 (He et al., 2015, He et al., 2016) 最具有代表性(以及近期提出的ViT模型 (Dosovitskiy et al., 2021) )。而其中ResNet的影响最为深远,它在将神经网络的深度扩展至数百层的同时还能保持很好的收敛性,在ImageNet的1000类图像分类任务中达到了4.94%的Top-5错误率,第一次超越了人类。相关研究估计 (Russakovsky et al., 2015) ,人类在1000类的ImageNet图像分类任务中的Top-5错误在为5.1%左右。虽然从2018年开始ImageNet比赛已不再举办,后续的研究工作已经将ImageNet图像分类任务的Top-5准确率逐步提高到了99%(Top-1准确率也达到了91%)。而在自然语言处理领域,深度学习也以不可抗拒之势席卷各大顶级会议和期刊,从2013年的word2vec (Mikolov et al., 2013) 到后来的LSTM (Hochreiter and Schmidhuber, 1997) 、GRU (Cho et al., 2014) 等经典模型,性能不断提升。2017年,谷歌公司发表论文《Attention Is All You Need》 (Vaswani et al., 2017) ,基于自注意力机制(self-attention)构建了Transformer模型,登上了各大自然语言处理任务的榜首。到2022年底,基于Transformer架构的各类大规模预训练模型则刷新了众多大自然语言处理任务的最优性能,并在计算机视觉领域也开始广泛应使用 (Dosovitskiy et al., 2021) ,呈现出模型结构大一统的趋势,再加上多模态学习的飞速发展,相信实现通用人工智能并不遥远。
AlphaGo战胜世界围棋冠军李世石。 2016年1月27日,DeepMind公司开发的计算机围棋程序AlphaGo (Silver et al., 2016) 在一项赛事中以5:0的成绩战胜了欧洲围棋冠军樊麾,这是计算机围棋程序首次在比赛中击败人类围棋专业高手,而这只是一个开始。2016年3月,AlphaGo挑战世界围棋冠军李世石,从3月9日到3月15日,AlphaGo连下三城以碾压的姿态赢得了代表人类最高水平的韩国职业棋手李世石,并最终以4:1取胜。一时间引发全社会的广泛关注,因为这代表着继深蓝拿下国际象棋十八年之后,曾被认为代表人类最高智力水平的围棋游戏也被人工智能攻克。在AlphaGo之后,DeepMind继续推出能力更加“变态”的AlphaGo Zero (Silver et al., 2017) ,其在经过三天的自我对战之后便战胜了之前战胜李世石的AlphaGo版本,更是在40天之后超过此前所有的AlphaGo版本。
自动驾驶汽车上路行驶。 实现汽车的自动驾驶是人类由来已久的梦想。从最初七十年代中期每移动1米都要花费20分钟的Stanford Cart(被普遍认为是第一辆自动驾驶汽车)到1995年卡耐基梅隆大学穿越美国的庞蒂克(美国通用公司旗下品牌)Trans Sport——NavLab5,再到美国国防高级研究计划局(DARPA)在莫哈韦(Mojave)沙漠组织的第一场挑战赛,自动驾驶已经历经了几十年的历程。很多传统汽车企业(如福特)在几十年之前就已经开始自动驾驶的研究,但是直到2004年的DARPA挑战赛(DARPA Grand Challenge),自动驾驶才真正的进入人们的视野。 在2007年的城市挑战赛中,卡耐基梅隆与通用汽车合作制造的“Boss”使用了一种全新的激光雷达扫描系统,这也是当今自动驾驶的一种主流解决方案。正是这些挑战赛的出现极大的促进了自动驾驶这个领域的蓬勃发展,2009年谷歌建立了一支由塞巴斯蒂安·特伦(Sebastian Thrun)领导的自动驾驶研发团队,三年后这支团队从谷歌分离出来成立了Waymo公司。2011年10月,谷歌在内华达州对自动驾驶的汽车进行测试,成为全球第一个进行无人驾驶汽车公路测试的公司。2012年5月,谷歌获得美国首个自动驾驶车辆许可证。不仅在美国,自动驾驶在大洋彼岸的中国也在如火如荼的进行中。2018年12月,百度的Apollo自动驾驶全场景车队在长沙高速上行驶。2019年6月,长沙人民政府颁发49张自动驾驶测试牌照,其中百度独得45张。2019年9月,百度自动驾驶出租车队Robotaxi在长沙试运营正式开启,这也是自动驾驶在中国商业化应用的一个里程碑事件。相信自动驾驶会在未来十年得到迅速的发展,有望给人们的生活与出行带来全新的体验。
AlphaFold 2 解决了困扰科学家50年之久的蛋白质折叠问题。 如果说以上关于棋类比赛、图像识别、以及自动驾驶的例子都是人工智能在实际应用层面的成功探索,那另外一个不得不提的例子就是2020年11月底DeepMind提出的AlphaFold算法 (Jumper et al., 2021) ,其破解了困扰科学家50年之久的蛋白质分子折叠问题。这个例子展现了人工智能技术在基础科学领域的巨大进步。 蛋白质是组成人体细胞、组织的重要成分,几乎所有的人类生命活动,如光亮感知、肌肉伸缩等,都离不开蛋白质的参与。因此,研究蛋白质折叠问题,即如何根据蛋白质的氨基酸序列来确定它的空间结构,对于生物学具有极其重要的意义。然而,这一研究问题困扰了生物科学家长达50年之久。 AlphaFold在2020年的国际蛋白质结构预测(CASP)比赛中,击败了其他的参赛队伍,以明显的优势拿下了比赛冠军。此外,AlphaFold的在准确度方面也可比肩人类实验结果,基本可以被认为在很大程度上解决了蛋白质的折叠预测问题。 DeepMind的这一突破性成果受到了学术界前所未有的关注和赞誉,CASP组织者、科学家安德烈·克里斯塔福维奇(Andriy Kryshtafovych)在大会上感叹:“我从没想过有生之年能看到这项技术的诞生。” 生物学家安德烈·鲁帕斯(Andrei Lupas)评价该技术:“将改变医学,改变研究,改变生物工程,甚至改变一切。” 这一重大突破证明了深度学习技术在解决基础科学问题方面的强大能力,展现了人工智能在基础科学领域的惊人发展潜力。
1.3. 人工智能安全¶
1.3.1. 数据与模型安全¶
在上一小节中我们看到人工智能在不同领域的成功应用,未来可预见的是,人工智能技术将不断蓬勃发展,更加深入到我们生产生活的方方面面。然而,作为一项新技术,我们必须认识到人工智能技术是一把双刃剑。因此,我们在享受人工智能带来的诸多便利的同时,也不能忽视随之而来的安全问题。当技术被赋能,一个安全性不足的智能系统所能带来的伤害是不可估量的。此外,随着技术的发展,人工智能是否会真正超越人类智能,是否还能够完全可控,这都是永远都不能忽视的重要问题。
根据安全问题所涉及的作用对象以及作用效果的不同,人工智能安全大致可以分为以下三类 (方滨兴, 2020) :人工智能内生安全、人工智能衍生安全、以及人工智能助力安全。人工智能内生安全指的是由于技术本身的脆弱性所引发的智能系统本身出现的安全问题,其作用对象是系统本身。理论上,任何一个智能系统的组件,如训练所使用的人工智能框架、训练数据、模型结构等,都有可能出现安全问题。 人工智能衍生安全指的是由于智能模型的不安全性而给其他领域带来的安全问题,其作用对象是智能系统以外的其他领域。自动驾驶事故、智能体脱离控制甚至攻击人类等就属于人工智能给交通和公共安全领域带来的衍生安全问题。 从作用效果来看,不管是内生安全还是衍生安全,我们一般认为其引发的安全问题都是负面有害的。与之相反,人工智能助力安全指的是利用人工智能技术为其他领域提升安全性,其作用是正向有益的。典型的人工智能助力安全的例子包括利用人工智能技术进行电脑病毒检测、虚假视频检测、危险事故预判等等。 尽管每一类安全问题都不容小觑,但是一个完全安全可靠的人工智能系统除了技术之外,还需要依托国家政策、法律法规、行业规范等多方约束。本书重点关注由于技术本身的不完善性而引发的人工智能内生安全问题,即人工智能系统构建过程中所面临的数据安全和模型安全。
数据安全。 人工智能的核心是机器学习。经过几十年的发展,机器学习衍生出有监督学习、无监督学习、强化学习、联邦学习、对比学习、特征学习等不同的学习范式,但不管是哪一种学习范式,要构建智能系统(模型)都离不开训练数据。可以说,训练数据的特性,如数据规模、数据均衡性、标注准确性等,在很大程度上直接决定了智能系统的最终表现。一般来说,数据规模越大,训练得到的模型的表征能力和泛化能力也就越强。而数据的均衡性则会直接影响模型所学习知识的均衡性,即训练数据分布越均衡、不同类别间的分布偏差越小,人工智能算法的泛化效果往往也就越好。标注的准确性同样也是影响人工智能内生安全的一个重要因素。由于标注工作的繁重性及其对专业知识的要求,标注过程中难免会产生一些错误,这会对人工智能算法的执行效果产生不可估量的影响。由于训练数据对最终模型的决定性作用,其也就成为攻击者的重点攻击对象,此外,数据中所包含的隐私和敏感信息也是攻击者的攻击目标。现有针对训练数据的攻击主要包括以下四种:
数据投毒:通过操纵数据收集或标注过程来污染(毒化)部分训练样本,从而大幅降低最终模型的性能。
数据窃取:从已训练好的模型中逆向工程出训练样本,从而达到窃取原始训练数据的目的。
隐私攻击:利用模型的记忆能力,挖掘模型对特定用户的预测偏好,从而推理出用户的隐私信息。
数据篡改:利用模型的特征学习和数据生成能力,对已有数据进行篡改或者合成全新的虚假数据。
模型安全。 模型无疑是人工智能系统最核心的部分。 高性能的模型是解决实际问题的关键,无论采用何种训练数据、训练方式、超参数选择,最终也往往都作用在模型上。因此,模型也就成为攻击者的首要攻击目标。现有针对人工智能模型的攻击大致可分为以下几类:
对抗攻击:在测试阶段向测试样本中添加对抗噪声,让模型作出错误预测结果,从而破坏模型在实际应用中的性能。
后门攻击:以数据投毒或者修改训练算法的方式,向模型中安插精心设计的后门触发器,从而在测试阶段操纵模型的预测结果。
模型窃取:通过与目标模型交互的方式,训练一个窃取模型来模拟目标模型的结构、功能和性能。
1.3.2. 现实安全问题¶
本小节介绍几个与人工智能数据与模型安全相关的真实案例,以此来警示相关问题可能会给社会以及个人所带来的危害,说明人工智能安全研究的重要性。
微软机器人Tay遭投毒攻击导致其发表歧视性言论:2016年3月25日,微软在其公司Twitter账户上推出了一款名为Tay的人工智能聊天机器人。Tay最初被寄予的期望是能够积极正向地与Twitter上的年轻人进行交流。然而,在上线不到24个小时内,Tay就由于受到网友的恶意投毒攻击,学会了发表恶意和歧视性言论,如支持纳粹主义、反对女性主义等言论,引起了大量Twitter用户的不适。这一结果直接导致微软在上线当天就关闭了Tay。
RealAI 基于对抗样本设计的眼镜成功解锁多款安卓手机: 2021年初,一则关于基于对抗样本设计的手机解锁技术引发了大众关注。清华大学人工智能研究所成立的RealAI公司研究显示,攻击者基于一张照片和对抗样本所设计的特殊眼镜可以在15分钟内解锁19款安卓手机以及金融领域的人脸识别系统。一旦人脸识别系统被攻破,将会给用户隐私、财产安全等带来巨大损失。
针对自动驾驶的对抗攻击案例:自动驾驶作为人工智能应用的典范,其安全性受到了研究者的广泛关注。Eykholt等人在其发表在CVPR 2018的论文 (Eykholt et al., 2018) 中展示了一种针对道路标志的物理对抗攻击,该攻击对路牌等重要交通标志牌添加不起眼的对抗贴纸,即使在不同拍摄角度、距离、光照等情况下,也能成功误导深度学习模型对路牌做出错误的识别,例如将“停止”标识识别为“45公里限速”。Eykholt等人提出的对抗攻击方法只是针对摄像机的攻击,而Cao等人 (Cao et al., 2021) 则是更进一步完成了对摄像机(形状改变)和雷达(点云改变)的同时攻击,可以让汽车“看不见”3D打印的对抗物体。
数据篡改与生成技术伪造虚假视频内容: 2017年,一名外国网友将色情视频中的女主角篡改为某知名女明星,给女性文娱工作者带来巨大的困扰与担扰。国内也发生过类似事件,2019年网上一段关于某女明星换脸为另外一位女明星的视频在各大社交媒体中广泛传播,引起了大众讨论。换脸技术甚至一度被应用到了政治领域,著名领导人奥巴马、特朗普、普京、汤姆·克鲁斯、已逝英国女王伊丽莎白二世等均有相关的虚假换脸视频被传出,其中美国前总统奥巴马的虚假视频在Youtube上的观看量高达960万次。在此前的俄乌冲突中也出现了一起伪造乌克兰总统呼吁全国人民放下武器的虚假讲话视频,给本就紧张的俄乌局势带来更多的不确定性。基于人工智能的数据篡改与伪造具有门槛低、成本低、效率高、传播性高等特点,一旦被恶意使用,将会引发严重的负面社会影响,严重时甚至会危害社会稳定。
在本书中,我们将部分隐私性问题(如隐私攻击、数据窃取和模型窃取)归纳为安全性问题,因为这些问题本身往往涉及多个方面(隐私和安全)。除了安全问题,数据和模型还可能会存在更广泛的可信性问题,如公平性问题、可解释性问题、隐私性问题等。例如,亚马逊人脸识别系统Rekognition将美国国会议员中的28人误判为罪犯,引发了公平性担忧;英国智能交通监控系统将行人衣服上的字母误识别为车牌号并开罚单;由于模型的不可解释性,《自然》子刊的一项研究发现新冠诊断模型根据X光片上的医院编码预测新冠肺炎而并不是实际的病理特征 (DeGrave et al., 2021) 。此外,在人工智能系统构建的任何一个环节,如数据采集、模型训练或模型部署等,均存在潜在的安全问题。随着各类攻击技术的发展,攻击所需要的成本也越来越低,但其所带来的危害却越来越大、影响范围越来越广。与此同时,相信随着防御技术的不断提高,很多现有安全问题也都会在不久的将来得到很好的解决。
1.4. 本章小结¶
本章从人工智能的定义、人工智能的发展、以及人工智能安全三个方面出发,简要概述人工智能发展背后的故事以及现有人工智能系统可能存在的数据与模型安全问题。其中人工智能的定义小节回顾了标志着人工智能概念诞生的1956年的达特茅斯会议,并对人工智能进行了解释;人工智能的发展小节重点介绍了人工智能的三起三落以及人工智能发展过程中的几个具有重大突破性的历史事件;人工智能安全小节首先给出了三类人工智能安全问题的定义及其关系:人工智能内生安全、人工智能衍生安全、以及人工智能助力安全,随后介绍了内生安全中的数据安全与模型安全问题,并在最后举例了几个现实发生的安全问题。希望这些介绍可以帮助读者更好的了解相关的背景。